Description
Background
This is a “HOW-TO” guide on using !Tsuite to read from an Excel spreadsheet and transport the data into an Access database, either updating an existing row or inserting a new row depending on the incoming data and the destination data set.
Submitted by
OS Version
!Tsuite Version
Problem
Need to transfer data from an Excel Spreadsheet to a Microsoft Access database
Solution
Preparation
To accomplish our task we create a Loader job, which once constructed will do all that is necessary to accomplish the final desired outcomes.
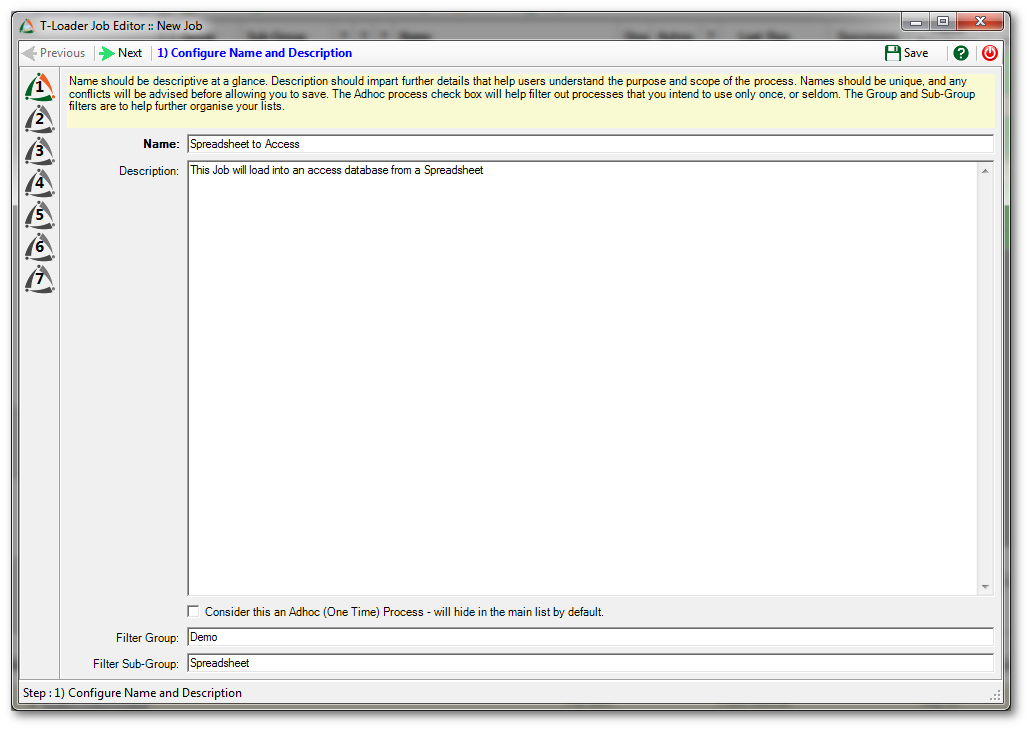
Step 1
First, we create a new !Tsuite Loader job, giving it a reasonable name and description, as well as any group filtering information desired.
Step 2
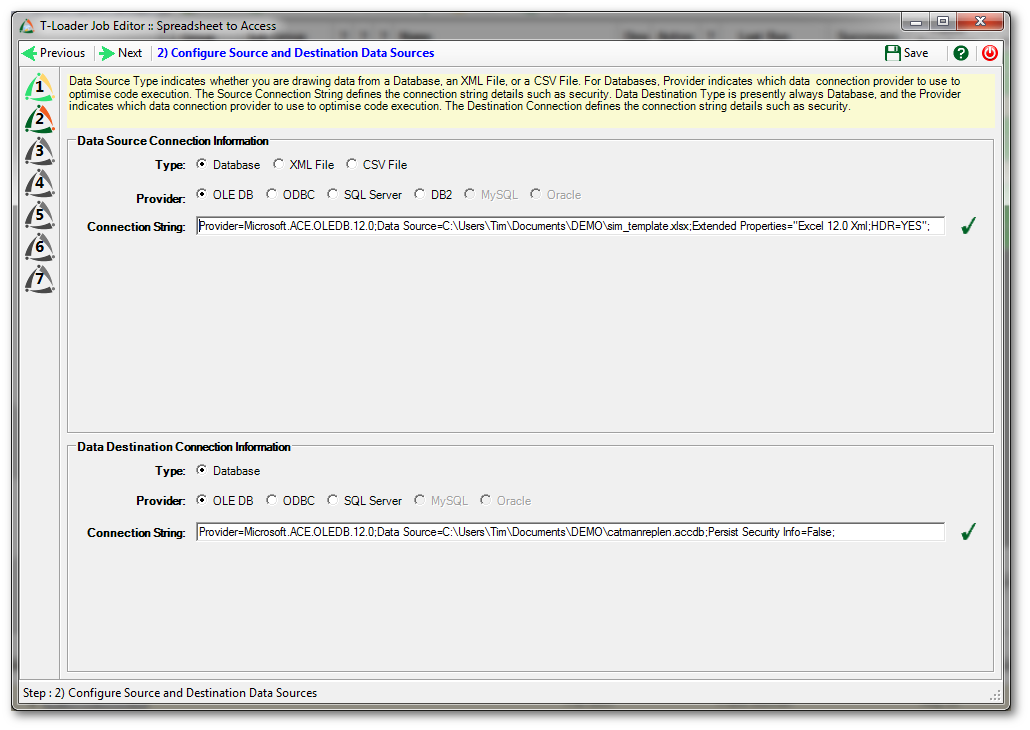
In the second stage of our job design we define the source and destination data points.
First we indicate where we are getting our data from. Because Microsoft Excel spreadsheets are accessed via the Microsoft Access Database Engine we must configure the data source details to use that provider. The type will be Database, the provider type OLE DB, and the connection string is constructed according to the model required for the Microsoft Access Database Engine.
The model for the connection string is:
Provider=Microsoft.ACE.OLEDB.12.0; Data Source={?}; Extended Properties=”Excel 12.0 Xml; HDR=YES”;
The “{?}” is the full path and file name pointing at your Excel spreadsheet file. And the extended properties identify the version of Excel and, in this case, whether the first row is a column name header. More information about connection strings for the ACE provider for Excel can be found at: http://www.connectionstrings.com/ace-oledb-12-0/
Next, we indicate where the data will be going to. Again, we are using the Microsoft Access Database Engine, so the connection string is similar to the one attaching to the spreadsheet.
Provider=Microsoft.ACE.OLEDB.12.0; Data Source={?}; Persist Security Info=False;
Again the “{?}” points at the target Access database. The Persist Security Info attribute tells the connection whether to maintain security information, and in our case it is unnecessary so we specify False. Further information about using the ACE provider for Access connections can be found at: http://www.connectionstrings.com/access/
With the connections specified in the job we can now proceed.
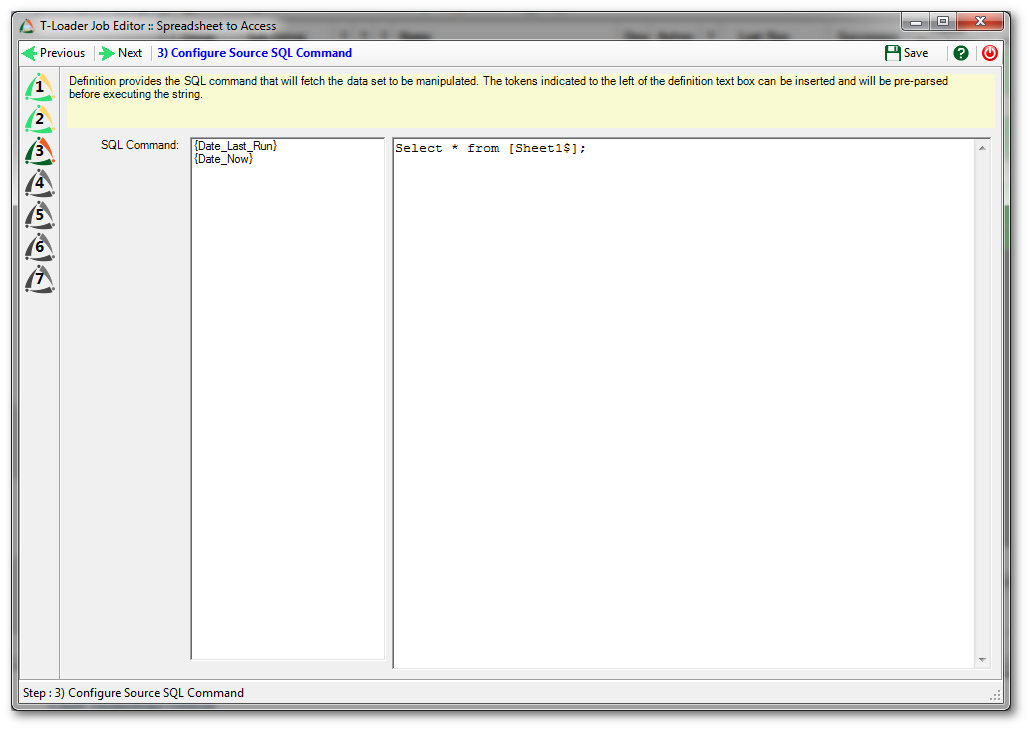
Step 3
The third step specifies how we will pull data from Excel. Because Loader jobs pull single data tables at a time, we need only to specify a SQL SELECT statement in a form the provider will interpret for Excel.
SELECT * FROM [Sheet1$];
The format for SQL to pull data from Excel is straightforward, and you can use an all-fields shorthand (the asterisk) or specify fields based upon the column names (if you used the “HDR=Yes” hint in your connection string). And the “table name” in an Excel workbook is the individual tab name. Here we have used the “Sheet1” tab. Square brackets should surround the tab name (they protect against spaces), and the tab name must be followed by a dollar sign ($). This is a necessity. It is also vital the tab name be exactly represented. So, for example, if the user has a tab named “my tab ” with a trailing space, the actual “table name” is “[my tab $]”. The most common errors people make here is that they forget the exact naming, or they forget to follow the name with the required dollar sign.
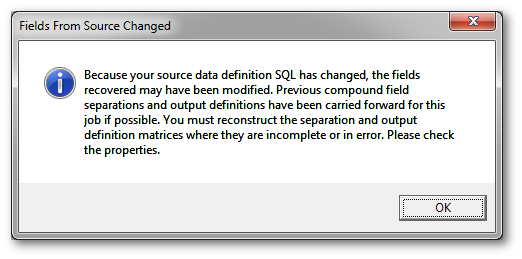
When you navigate to the next step the cache will be refreshed to allow you to proceed, returning a row of data for review in the process. Any time you change the SQL statement (or the provider resets its awareness of it) you will see this dialog box.
Step 4
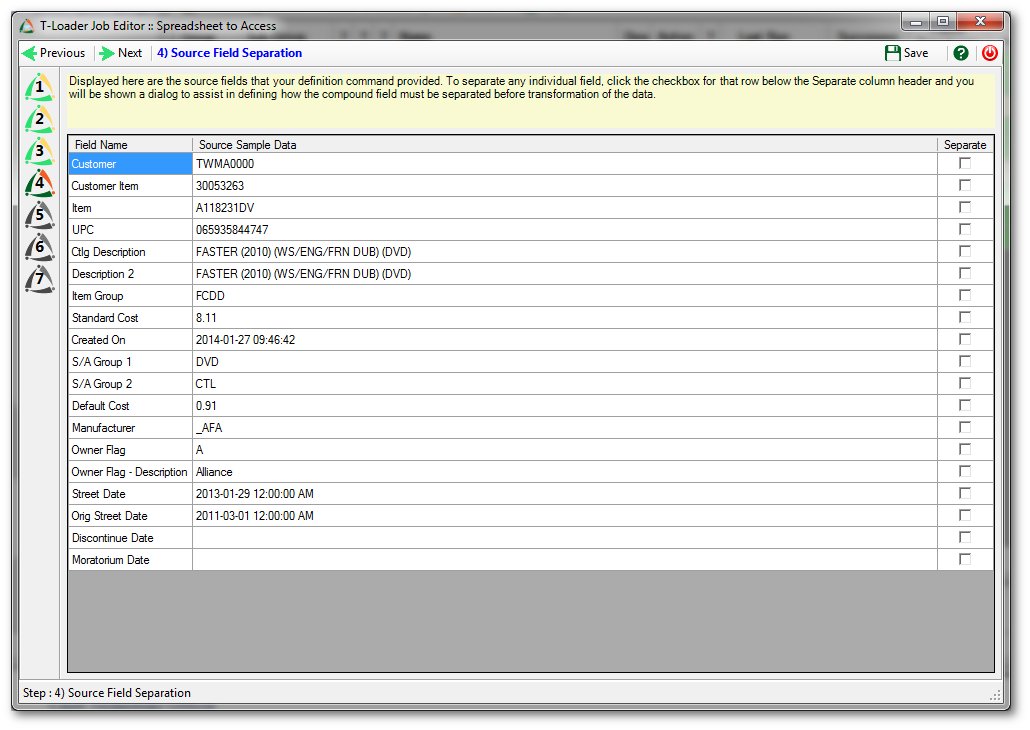
The fourth step shows us the fields pulled by our SQL statement, along with a sample row worth of data. To really proceed with full confidence you need to have some inherent awareness of your data, because though the sample row may show the range of expected incoming data, it is a single row and other rows may not conform as expected. A common issue is that field data that is incoming may be missing (NULL), and if your insertion and update logic requires that field to have data this can affect the execution of your logic.
This review screen also allows you to sub-separate fields. You can define a separation matrix for any individual field, making part of the contents field names and part data. Here we don’t actually require that level of separation, so this remains a purely review-step.
Step 5
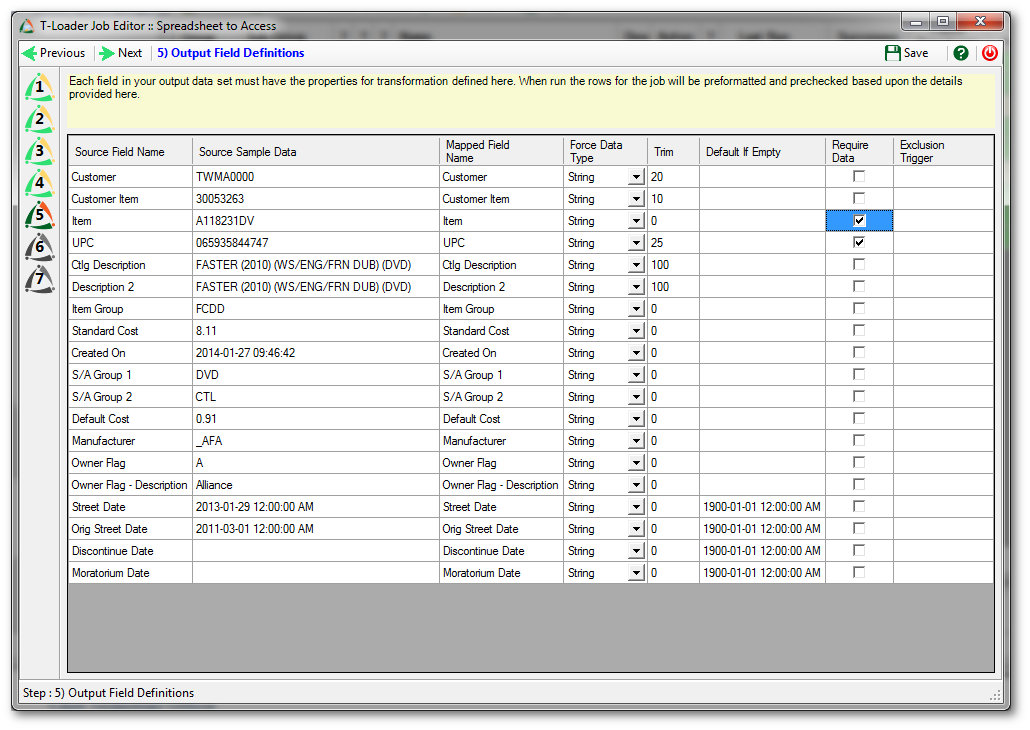
We can now define some rules about our output fields, including:
- Renaming the fields for clarity (the mapped field name);
- Force a data type (beware this, because if incoming data cannot be conformed to your chosen data type it will create errors);
- Trim the data in the field to a certain length (handy if the target table in the destination database has limitations to what can be stored in text fields);
- Provide a default if the data incoming is missing;
- Indicate if the row requires data in that field (an error row is generated if the data is missing for a required field); and
- Define an exclusion trigger (e.g., if the field data equals some value…discard that row).
Here we used the Trim column to shorten incoming text data, indicated two required fields, and ensured incoming dates contain a default.
Step 6
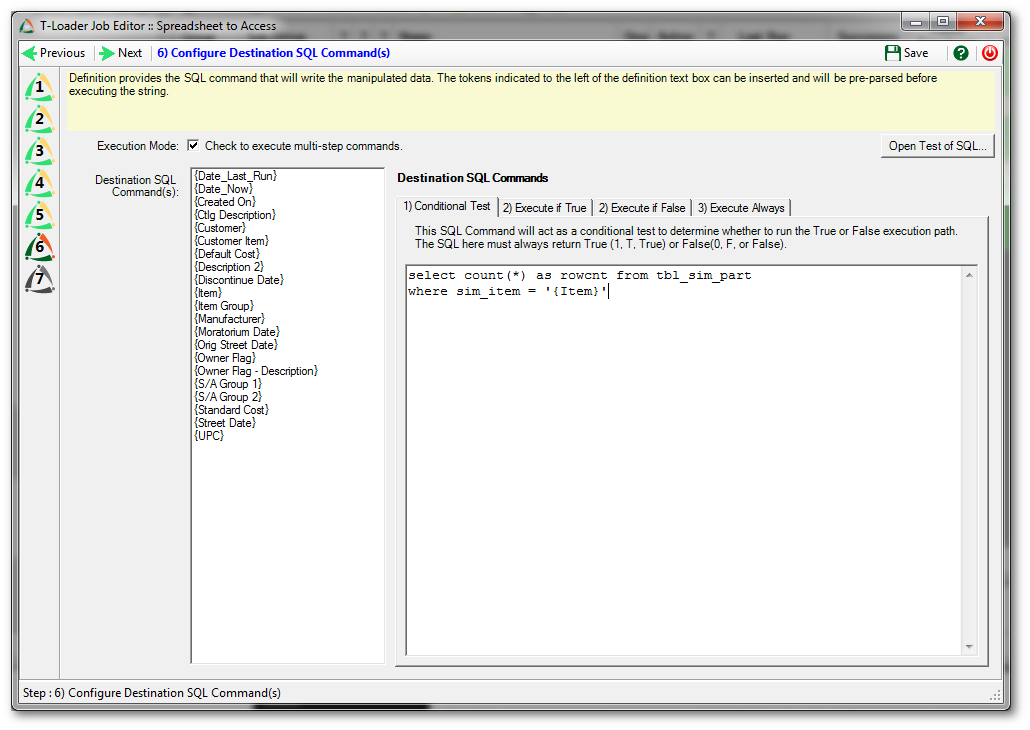
We are now ready to define how our data should be output into the destination database. In the case of this job we want to execute some conditional SQL, so we indicated the execution mode by checking the box by that label. This means we can test for something and then execute one SQL command if true, and another if false. We also have the ability to execute a command after the conditional effort.
To design our SQL commands we can type into the boxes, and use the handy left-side field list to insert tokens that will be translated into field data from those fields when the commands are finally prepared.
On the “Conditional Test” tab our test is to SELECT and count the rows in the table named “tbl_sim_part” where the “sim_item” field is equal to the value in the incoming “Item” field. Since a count can be converted to true or false (0 means false, 1 means true) this triggers our following logic.
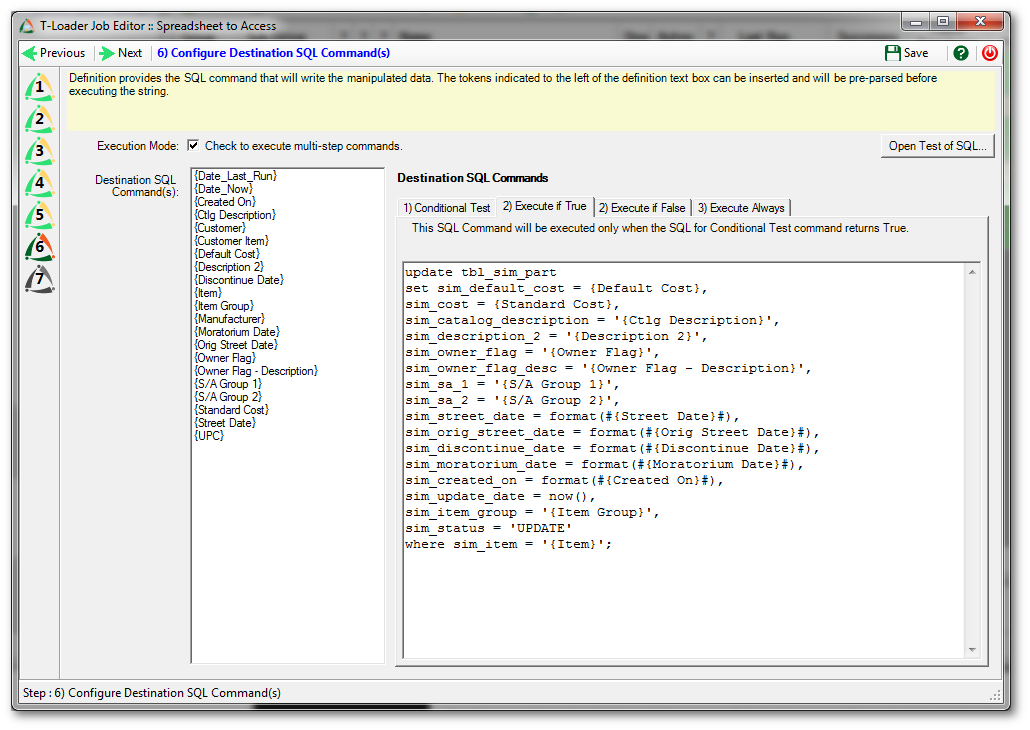
On the “Execute if True” tab we provide an UPDATE command that handles all the logic we want to happen if there is a matching row. In this case we will update the data rather than insert a new row, based upon a matching item number.
On the “Execute if False” tab we will indicate the logic that executes when the conditional test returns false (indicating now matching row). Here we decided to insert a new row, with the incoming values.
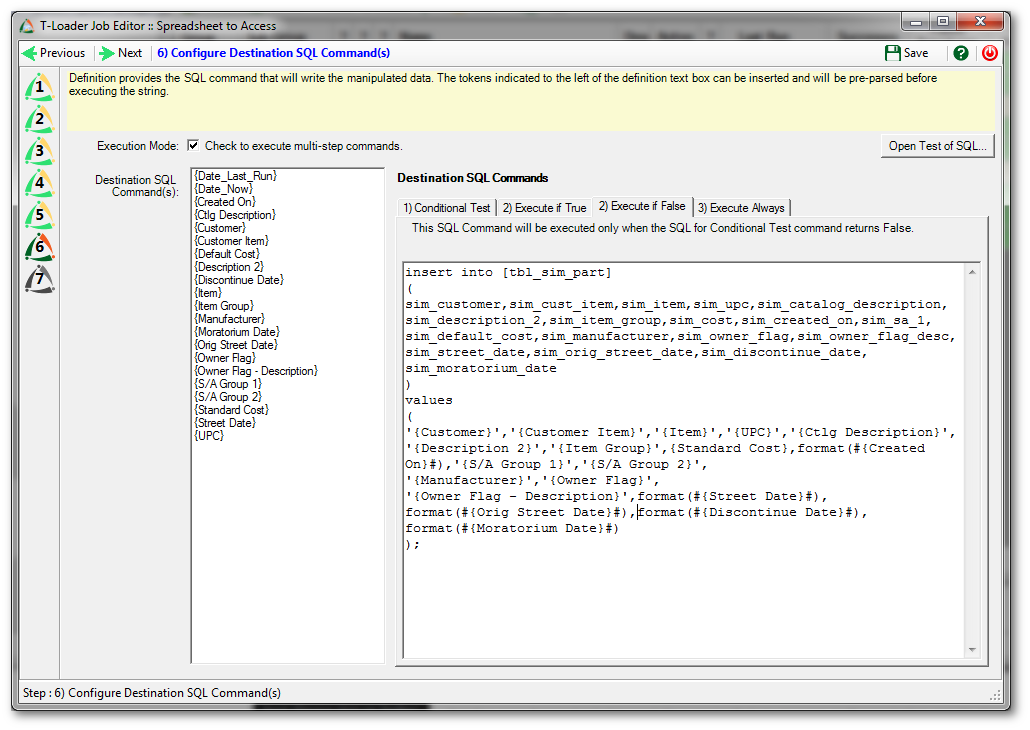
We can use the “Open Test of SQL” button in the interface to test the logic against our sample row. This can then be pasted, as desired, into a workbench product if we want to check our SQL’s validity.

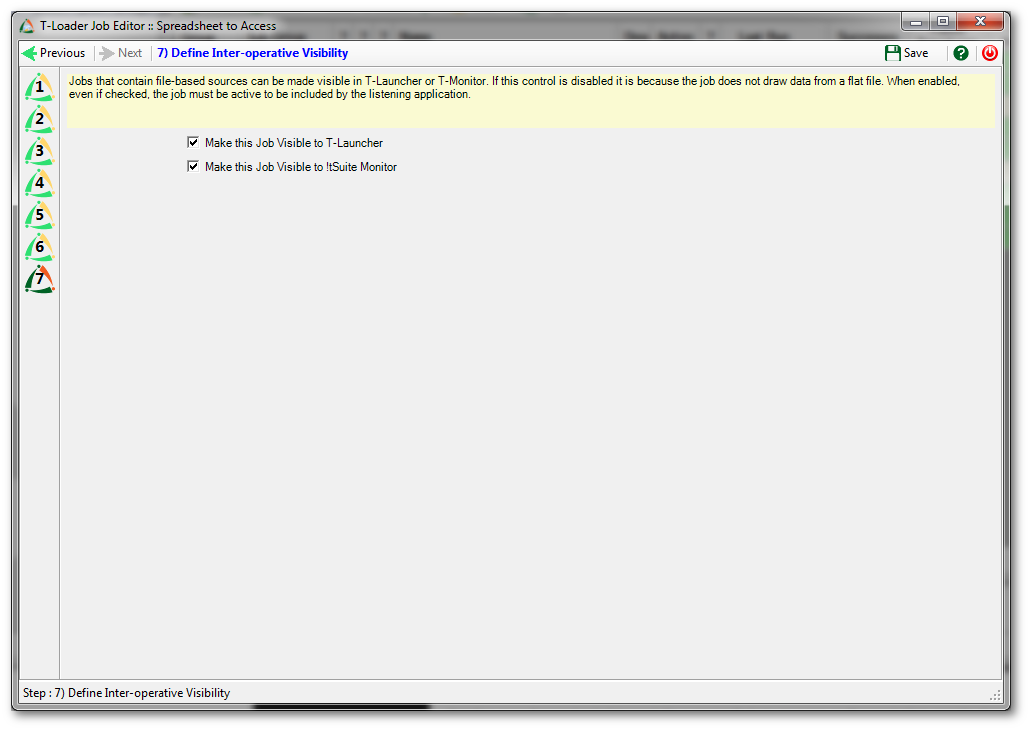
Step 7
Finally, we can set the visibility attributes for our new job before saving.
Completion
Once our job is saved we will see it in the Loader job list and to use it we:
- We change the job to Active, allowing it to run against the destination (until then it just runs as a test against the first 50 rows, producing the SQL but not executing it);
- When Active and we run the job the destination table in the MS Access database will be updated or have rows inserted based upon our logic.
Final Thoughts
The benefit of creating such a Loader job is that it will behave identically from one run to the next. This helps reduce manual labour and manage all sorts of data transfers.
More information
Please refer to knowledge base articles regarding HOW TO
| Description | Link |
| N/A | N/A |
| N/A | N/A |
| N/A | N/A |
| N/A | N/A |
| N/A | N/A |